Introdução à Recuperação de Informação #02 Modelagem

?? Saudações, galera! No post anterior fizemos uma pequena introdução à Recuperação de Informação (RI).
Neste post, vamos falar sobre modelagem de sistemas de RI. Bora! ?
Documentos, consultas e ranqueamento
Segundo Baeza-Yates e Ribeiro Neto (2013), a modelagem de um sistema de RI envolve duas etapas principais:
- A criação de uma estrutura lógica para representar documentos e consultas;
- A criação de um sistema de ranqueamento que calcula o grau de similaridade de cada um dos documentos de uma coleção (dataset) em relação a uma consulta.
Os documentos de um dataset podem ser representados de diversas maneiras. Normalmente o conteúdo bruto, que normalmente é não estruturado, é processado a fim de criar uma nova estrutura minimamente organizada.
Isso significa que documentos impressos ou digitais, sejam textuais, imagens, áudio ou vídeo, devem ser submetidos a transformações que objetivam uma representação que propicie sua leitura por meio de programas de computador.
É importante destacar que os termos de indexação (palavras-chave ou um grupo de palavras-chave relacionadas) são usados para indexar e realizar as consultas num sistema de RI. Esses termos normalmente são substantivos, mas podem ser qualquer palavra que apareça dos documentos do dataset.
Claro, além dos termos de indexação, há outros meios de realizar consultas, considerando aspectos semânticos, contextuais, posicionamento do termo no documento, além de técnicas de Inteligência Artificial.
Entretanto, como diversos autores na literatura apontam, a utilização de termos de indexação possui a vantagem de ser simples de implementar. Essa simplicidade considera:
- o esforço do usuário ao formular consultas;
- o esforço dos desenvolvedores ao formular sistemas de RI;
- o baixo poder computacional que exige esses sistemas.
Por outro lado, a principal desvantagem está na restrição semântica, considerando as poucas palavras-chave usadas nas consultas.
Sobre ranqueamento, ou seja, a função que classifica os documentos retornados pela consulta segundo sua relevância, é possível afirmar que talvez essas seja a parte mais importante de um sistema de RI.
Isso se dá devido ao fato de que o conceito de relevância é subjetivo, ou seja, dois usuários podem discordar sobre a relevância de um conjunto de documentos retornados por uma consulta.
Para lidar com esse problema, são propostos diversos modelos de RI que adotam diferentes algoritmos de ranqueamento que dispensam intervenção direta do usuário.
“Um algoritmo de ranqueamento opera de acordo com premissas básicas a respeito da noção de relevância de um documento. Diferentes conjuntos de premissas (a respeito da relevância de um documento) produzem modelos de RI diferentes”
BAEZA-YATES; RIBEIRO NETO (2013)
Caracterizando um modelo de RI
Segundo Baeza-Yates e Ribeiro Neto (2013), um modelo de RI é uma quádrupla representada por [D, Q, F, R(qi, dj)], em que:
- D é um conjunto composto por visões lógicas (ou representações) dos documentos da coleção;
- Q é um conjunto composto por visões lógicas (ou representações) das necessidades de informação dos usuários. Essas representações são chamadas de consultas;
- F é um arcabouço para modelar as representações dos documentos, das consultas e dos seus relacionamentos, como conjuntos de relações Booleanas, vetoriais e operações de álgebra linear, espaços amostrais e distribuições de probabilidade.
- R(qi, dj) é uma função de ranqueamento que associa um número real à representação de uma consulta qi ∈ Q e à representação de um documento dj ∈ D. Esse ranking define um ordenamento entre os documentos em relação à consulta qi.
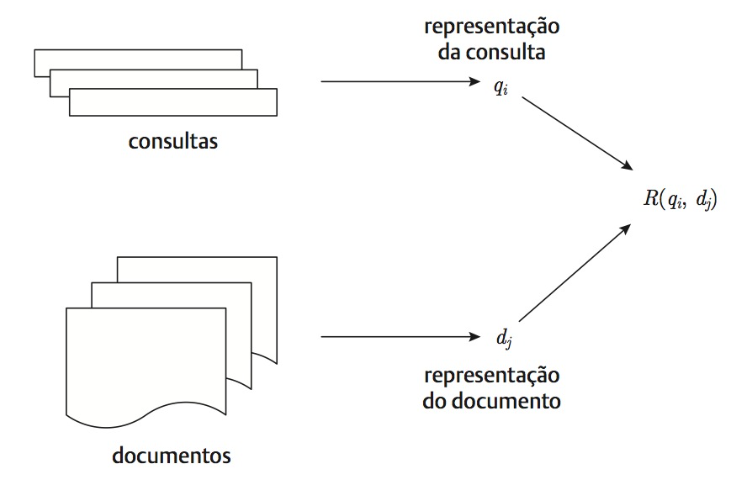
Considerando a quádrupla apresentada, é necessário construir as representações dos documentos e das consultas considerando as necessidades dos usuários.
Por exemplo, os documentos podem ser representados por um subconjunto de termos que pode ser obtido removendo-se as stop-words e usando técnicas como o stemming e a lematização.
As stop-words são termos irrelevantes para a consulta, ou seja, com baixo poder discriminativo, como por exemplo artigos e preposições. Por sua vez, a técnica de stemming consiste na remoção de prefixos e sufixos, reduzindo a palavra em sua forma base. Finalmente, a lematização consiste na redução das palavras a sua forma no masculino e singular (lemas), simplificando os termos do documento.
As consultas podem ser representadas por um superconjunto dos termos da consulta, formada pela consulta original e sinônimos, o que enriquece as possibilidade de encontrar documentos de interesse.
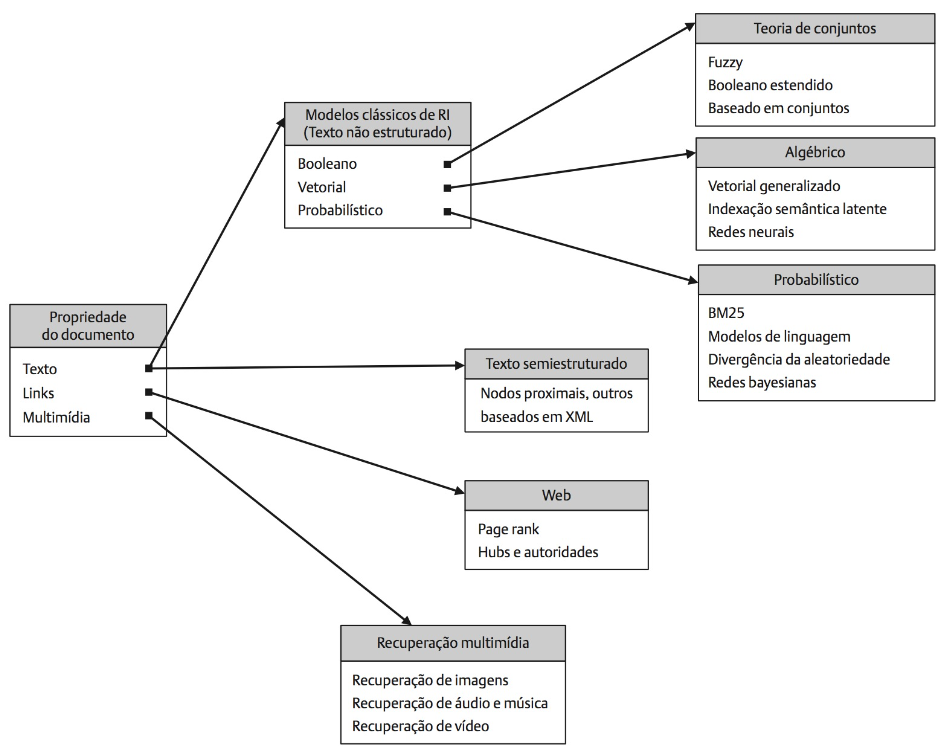
Modelos clássicos de RI
Considerando textos não estruturados, há 3 modelos clássicos:
Modelo Booleano
O modelo Booleano considera que os termos de indexação da consulta podem estar presentes ou ausentes no documento (pesos binários). Assim uma consulta q é composta por termos de indexação ligados pelos operadores booleanos not, and e or. Por sua simplicidade, foi o modelo mais usados no passado por muitos sistemas bibliográficos.
Modelo Vetorial
Ao contrário do modelo booleano, que admite pesos binários aos termos de indexação da consulta em relação ao documento, esse modelo admite pesos não binários que são usados para calcular o grau de similaridade entre os documentos do dataset e a consulta do usuário. Assim, os documentos recuperados são ordenados de maneira decrescente, considerando documentos que casam parcialmente com os termos de indexação usados na consulta.
Modelo Probabilístico
O modelo probabilístico parte da premissa de que mediante uma consulta do usuário, há um conjunto de documentos que compõem uma resposta ideal. Entretanto, essa resposta ideal não é conhecida, exigindo uma etapa inicial que determina uma descrição probabilística que define essa resposta. Assim, as interações com o usuário são iniciadas, em que ele indica quais documentos são relevantes ou não. O sistema usa essas respostas do usuário para melhorar a resposta ideal, refinando o sistema a cada iteração.
De fato, esse modelo, após inúmeros experimentos, é baseado na premissa de que a probabilidade de relevância dos documentos dependa somente das representações dos documentos e das consultas, e que existe um subconjunto de resultados que o usuário prefira como resposta ideal.
Taxonomia de modelos de RI
Além dos modelos clássicos, há diversos outros modelos, como aponta Baeza-Yates e Ribeiro Neto (2013):
Conclusão
Antes de conceber um sistema de RI é necessário considerar o problema a ser resolvido, e somente assim definir qual é o melhor modelo a ser implementado.
Os modelos clássicos apresentados aqui baseiam-se numa abordagem focada em termos de indexação (palavras-chave) que fazem parte dos documentos, conhecida como Bag of Word (BoW – saco de palavra).
Essa característica faz com que sistemas que implementem esses modelos sejam de simples implementação, além de possuir baixo custo computacional.
Nos próximos posts iremos discutir como implementar na prática alguns desses modelos.
Até lá! ??
Referências
BAEZA-YATES, R.; RIBEIRO-NETO, B. Recuperação de Informação: Conceitos e Tecnologia das Máquinas de busca. 2 ed. Porto Alegre: Grupo A, 2013.



